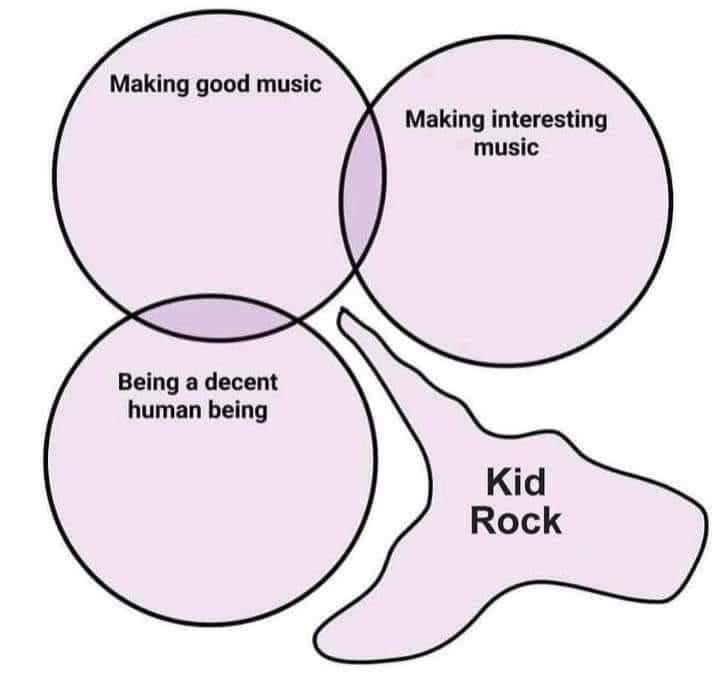
OK I’m stretching a little here, but… if I had a classification system, and had a data point that was outside of all my current sets, I might make a set for that one outlier. But there’s a valid criticism that the sets are poorly-named. The sets are better named: (Artists who make good music, Artists who make interesting music, Artists who are decent human beings, Artists who are Kid Rock). And yes, thus far any time the data analyst has seen artists who make interesting music, those artists have not been decent human beings. Presumably once the data analyst sees an artist who is musically interesting and decent, they’ll rearrange their diagrams. But the way it is now makes it look a little funnier.


{kind=link}
OK I’m stretching a little here, but… if I had a classification system, and had a data point that was outside of all my current sets, I might make a set for that one outlier. But there’s a valid criticism that the sets are poorly-named. The sets are better named: (Artists who make good music, Artists who make interesting music, Artists who are decent human beings, Artists who are Kid Rock). And yes, thus far any time the data analyst has seen artists who make interesting music, those artists have not been decent human beings. Presumably once the data analyst sees an artist who is musically interesting and decent, they’ll rearrange their diagrams. But the way it is now makes it look a little funnier.