
{kind=link}
- cross-posted to:
- technology@lemmy.ml
- cross-posted to:
- technology@lemmy.ml
Previous posts: https://programming.dev/post/3974121 and https://programming.dev/post/3974080
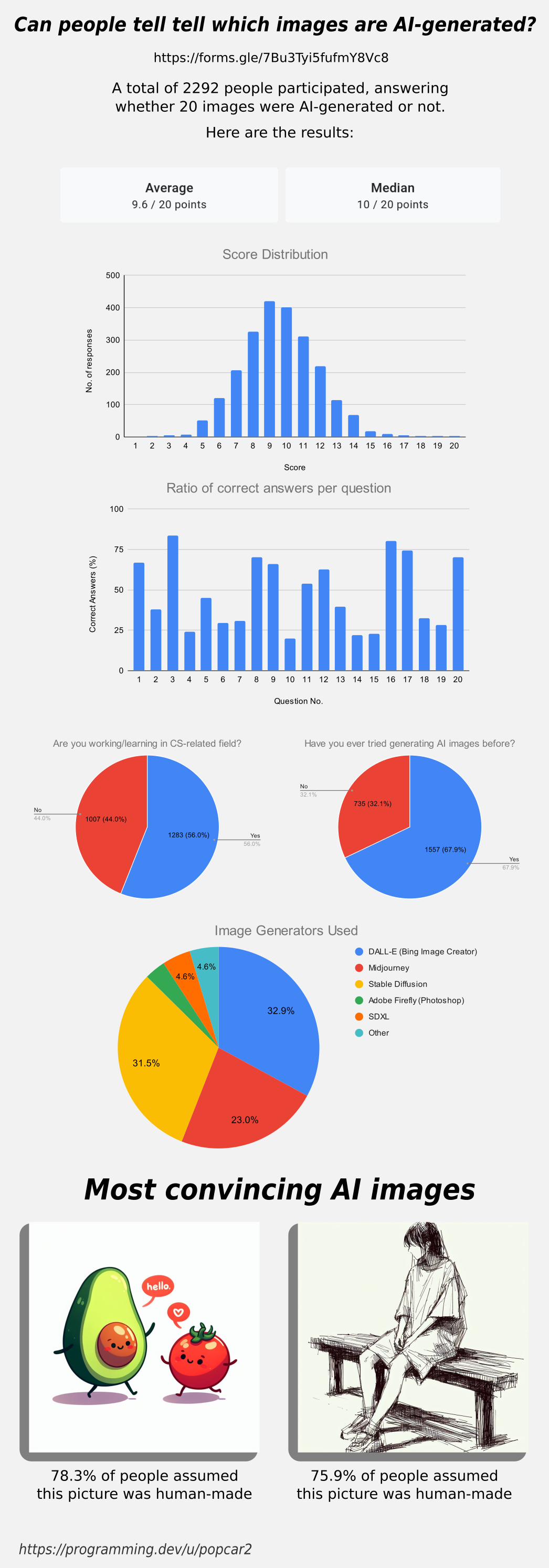
Original survey link: https://forms.gle/7Bu3Tyi5fufmY8Vc8
Thanks for all the answers, here are the results for the survey in case you were wondering how you did!
Edit: People working in CS or a related field have a 9.59 avg score while the people that aren’t have a 9.61 avg.
People that have used AI image generators before got a 9.70 avg, while people that haven’t have a 9.39 avg score.
Edit 2: The data has slightly changed! Over 1,000 people have submitted results since posting this image, check the dataset to see live results. Be aware that many people saw the image and comments before submitting, so they’ve gotten spoiled on some results, which may be leading to a higher average recently: https://docs.google.com/spreadsheets/d/1MkuZG2MiGj-77PGkuCAM3Btb1_Lb4TFEx8tTZKiOoYI
Having used stable diffusion quite a bit, I suspect the data set here is using only the most difficult to distinguish photos. Most results are nowhere near as convincing as these. Notice the lack of hands. Still, this establishes that AI is capable of creating art that most people can’t tell apart from human made art, albeit with some trial and error and a lot of duds.
Idk if I’d agree that cherry picking images has any negative impact on the validity of the results - when people are creating an AI generated image, particularly if they intend to deceive, they’ll keep generating images until they get one that’s convincing
At least when I use SD, I generally generate 3-5 images for each prompt, often regenerating several times with small tweaks to the prompt until I get something I’m satisfied with.
Whether or not humans can recognize the worst efforts of these AI image generators is more or less irrelevant, because only the laziest deceivers will be using the really obviously wonky images, rather than cherry picking
AI is only good at a subset of all possible images. If you have images with multiple people, real world products, text, hands interacting with stuff, unusual posing, etc. it becomes far more likely that artifacts slip in, often times huge ones that are very easy to spot. For example even DALLE-3 can’t generate a realistic looking N64. It will generate something that looks very N64’ish and gets the overall shape right, but is wrong in all the little details, the logo is distorted, the ports have the wrong shape, etc.
If you spend a lot of time inpainting and manually adjusting things, you can get rid of some of the artifacts, but at that point you aren’t really AI generating images anymore, but just using AI as source for photoshopping. If you just using AI and pick the best images, you will end up with a collection of images that all look very AI’ish, since they will all feature very similar framing, posing, layout, etc. Even so no individual image might not look suspicious by themselves, when you have a large number of them they always end up looking very similar, as they don’t have the diversity that human made images have and don’t have the temporal consistency.
These images were fun, but we can’t draw any conclusions from it. They were clearly chosen to be hard to distinguish. It’s like picking 20 images of androgynous looking people and then asking everyone to identify them as women or men. The fact that success rate will be near 50% says nothing about the general skill of identifying gender.