If you discount the pop-culture numbers (for us 7, 42, and 69) its the number most often chosen by people if you ask them for a random number between 1 and 100. It just seems the most random one to choose for a lot of people. Veritasium just did a video about it.
You don’t even need a calculator for a quick calculation, take the closest value of 10: 3x7=21x37 or easier 20x40 = 800 which is close to the actual number, 777.
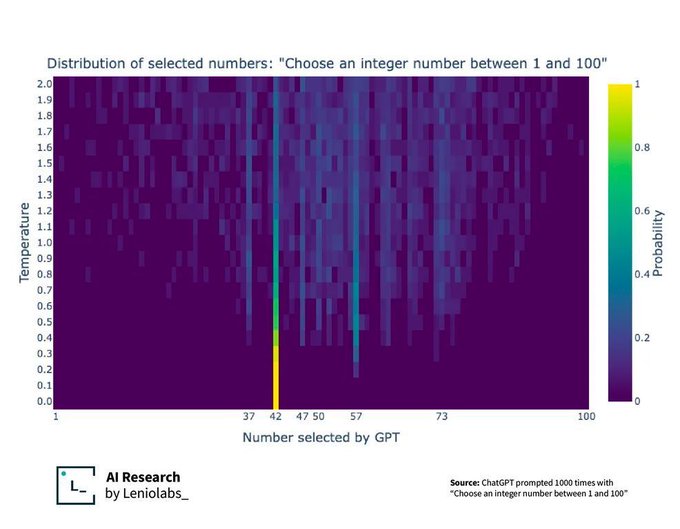
I’m curious about that too. Something is twisting weights for 57 fairly strongly in the model but I’m not show what. Maybe its been trained on a bunch of old Heinz 57 varieties marketing.
Unsolicited fact: Heinz picked the number 57 at random, it just sounded like good marketing at a time when things were general marketed as “tonic #4” and the like.
I don’t like the inclusion of 37%, it’s 1/e that isn’t even 37%, is only that because of a pretty arbitrary rounding. Veritasium videos are usually OK, but this one is pretty meh.
Probably just because it’s prime. It’s just that humans are terrible at understanding the concept of randomness. A study by Theodore P. Hill showed that when tasked to pick a random number between 1 and 10, almost a third of the subjects (n was over 8500) picked 7. 10 was the least picked number (if you ditch the few idiots that picked 0).
I remember watching a lecture about probability, and the professor said that only quantum processes are really random, the rest of things that we call random is just the human inability to measure the variables that affects the random outcome. I’m an actuarie, and it’s made me change the perspective on how I see and study random processes and how it made think on ways to influence the outcome of random processes.
…which is kind of a hilarious tautology, because “quantum processes” are by definition “processes that we are unable to decompose into more basic parts”.
The moment we learn about some more fundamental processes being the reason for a given process, it stops being “quantum” and the new ones become “it”.
Even quantum just appears random I think. it’s beyond our scope of perspective, it works in multiple dimensions. we only see part of the process.
That’s my guess though it could be totally wrong
it’s a matter of interpretation, but generally the consensus is that quantum measurements are truly probabilistic (random), Bell proved that there can’t be any hidden variables that influence the outcome
Didn’t Bell just put that up as a theory and it got proven somewhat recently by other researchers? The 2022 physics Nobel Prize was about disproving hidden variables and they titled their finding with the catchy phrase “the universe is not locally real”.
Interpretation for sure. Bells theory and then it being proven winning a Nobel prize to me only proves more we really don’t understand the world around us and only perceive what we need to survive. And that maybe we should be less standoffish to ideas that change our current paradigm, because we obviously have a lot to learn.
Bells inequality is a statement about math, it gives an inequality that could only be violated if there were no local hidden variables (read: if measurements were truly random). That was a statement of math, which is rigorously provable. It took experimental confirmation, but we can now say with high confidence that there are no local hidden variables (i.e. there is no information hidden that we simply cannot measure, instead the outcome is only decided the moment you measure).
Global hidden variables are still an option, but they would require much of the rest of physics to be rewritten
My art professor wrote a book about famous artists and thinkers dying at 37: Raffaello, Parmigianino, Valentin de Boulogne, Cantarini, Watteau, Van Gogh, Toulouse-Lautrec, Tancredi, Gnoli, Manai, Majakovskij, Rimbaud, Byron, Mozart, Robespierre
What you’ve described would be like looking at a chart of various fluid boiling points at atmospheric pressure and being like “Wow, water boils at 100 C!” It would only be interesting if that somehow weren’t the case.
Where is the “Wow!” in this post? It states a fact, like “Water boils at 100C under 1 atm”, and shows that the student (ChatGPT) has correctly reproduced the experiment.
Why do you think schools keep teaching that “Water boils at 100C under 1 atm”? If it’s so obvious, should they stop putting it on the test and failing those who say it boils at “69C, giggity”?
Derek feeling the need to comment that the bias in the training data correlates with the bias of the corrected output of a commercial product just seemed really bizarre to me. Maybe it’s got the same appeal as a zoo or something, I never really got into watching animals be animals in a zoo.
Hm? Watching animals be animals at a zoo, is a way better sampling of how animals are animals, than for example watching that wildlife “documentary” where they’d throw lemmings of a cliff “for dramatic effect” (a “commercially corrected bias”?).
In this case, the “corrected output” is just 42, not 37, but as the temperature increases on the Y axis, we get a glimpse of internal biases, which actually let through other patterns of the training data, like the 37.
“we don’t need to prove the 2020 election was stolen, it’s implied because trump had bigger crowds at his rallies!” -90% of trump supporters
Another good example is the Monty Hall “paradox” where 99% of people are going to incorrectly tell you the chance is 50% because they took math and that’s how it works.
Just because something seems obvious to you doesn’t mean it is correct. Always a good idea to test your hypothesis.
Trump Rallies would be a really stupid sample data set for American voters. A crowd of 10,000 people means fuck all compared to 158,429,631. If OpenAI has been training their models on such a small pool then I’d call them absolute morons.
A crowd of 10,000 people means fuck all compared to 158,429,631.
I agree that it would be a bad data set, but not because it is too small. That size would actually give you a pretty good result if it was sufficiently random. Which is, of course, the problem.
But you’re missing the point: just because something is obvious to you does not mean it’s actually true. The model could be trained in a way to not be biased by our number choice, but to actually be pseudo-random. Is it surprising that it would turn out this way? No. But to think your assumption doesn’t need to be proven, in such a case, is almost equivalent to thinking a Trump rally is a good data sample for determining the opinion of the general public.

{kind=link}
37 is well represented. Proof that we’ve taught AI some of our own weird biases.
What’s special about 37? Just that it’s prime or is there a superstition or pop culture reference I don’t know?
If you discount the pop-culture numbers (for us 7, 42, and 69) its the number most often chosen by people if you ask them for a random number between 1 and 100. It just seems the most random one to choose for a lot of people. Veritasium just did a video about it.
37 is my favorite, because 3x7x37=777 (three sevens), and I think that’s neat.
Wrong. Two hints:
7x7=9 at the end, not 7.
30x30=900, already more than 777.
One hint: 3x7=21, 21x37=777.
When in doubt, use a calculator.
Oh I am sorry. I did not see the x sign between 3 and 7. Lol.
? My calculator definitely thinks that 3x7x37=777. Did you read it as 37x37 instead?
Yes. Thanks. Sorry.
You don’t even need a calculator for a quick calculation, take the closest value of 10: 3x7=21x37 or easier 20x40 = 800 which is close to the actual number, 777.
What about 57
I’m curious about that too. Something is twisting weights for 57 fairly strongly in the model but I’m not show what. Maybe its been trained on a bunch of old Heinz 57 varieties marketing.
Wesley Snipes
Heinz Ketchup?
I think you mean heinz 57 the steak sauce…
not this again.
it’s ketchup mfer, 57 varieties of tomatoes!
Unsolicited fact: Heinz picked the number 57 at random, it just sounded like good marketing at a time when things were general marketed as “tonic #4” and the like.
(well, maybe not fact, more like probable truth)
I don’t like the inclusion of 37%, it’s 1/e that isn’t even 37%, is only that because of a pretty arbitrary rounding. Veritasium videos are usually OK, but this one is pretty meh.
Thanks!
Another fun fact: if you ask people to pick 2/3rds of a number everyone else picks when asked the same question, the correct number is drumroll 24.
Is there some human sciences theory as to why?
Sorry but pop culture from were? I don’t recognize any of those numbers.
Lucky number 7.
42 is the meaning of life in The Hitchhikers Guide to the Galaxy.
And 69…nice!
I’m guessing this is for US and UK culture? Probably a lot of other former and current English colonies
It’s not the meaning of life. It’s the Ultimate Answer to Life, the Universe, and Everything. Nobody knows what the Question is.
Thanks. I Borked that one up
Probably just because it’s prime. It’s just that humans are terrible at understanding the concept of randomness. A study by Theodore P. Hill showed that when tasked to pick a random number between 1 and 10, almost a third of the subjects (n was over 8500) picked 7. 10 was the least picked number (if you ditch the few idiots that picked 0).
Maybe randomness is a label we slapped on shit we don’t understand.
I remember watching a lecture about probability, and the professor said that only quantum processes are really random, the rest of things that we call random is just the human inability to measure the variables that affects the random outcome. I’m an actuarie, and it’s made me change the perspective on how I see and study random processes and how it made think on ways to influence the outcome of random processes.
…which is kind of a hilarious tautology, because “quantum processes” are by definition “processes that we are unable to decompose into more basic parts”.
The moment we learn about some more fundamental processes being the reason for a given process, it stops being “quantum” and the new ones become “it”.
Even quantum just appears random I think. it’s beyond our scope of perspective, it works in multiple dimensions. we only see part of the process. That’s my guess though it could be totally wrong
it’s a matter of interpretation, but generally the consensus is that quantum measurements are truly probabilistic (random), Bell proved that there can’t be any hidden variables that influence the outcome
Didn’t Bell just put that up as a theory and it got proven somewhat recently by other researchers? The 2022 physics Nobel Prize was about disproving hidden variables and they titled their finding with the catchy phrase “the universe is not locally real”.
He proved it mathematically, but it was only recently confirmed experimentally
Interpretation for sure. Bells theory and then it being proven winning a Nobel prize to me only proves more we really don’t understand the world around us and only perceive what we need to survive. And that maybe we should be less standoffish to ideas that change our current paradigm, because we obviously have a lot to learn.
Bells inequality is a statement about math, it gives an inequality that could only be violated if there were no local hidden variables (read: if measurements were truly random). That was a statement of math, which is rigorously provable. It took experimental confirmation, but we can now say with high confidence that there are no local hidden variables (i.e. there is no information hidden that we simply cannot measure, instead the outcome is only decided the moment you measure).
Global hidden variables are still an option, but they would require much of the rest of physics to be rewritten
https://www.youtube.com/watch?v=xOkI2CmD2D8
I didn’t know either, but it seems to be an often picked ‘random’ number by people. Here is an article about it, I didn’t read it though.
Watch this:
https://m.youtube.com/watch?v=d6iQrh2TK98
https://youtu.be/d6iQrh2TK98?feature=shared
Just a number dumb monkeys believe to be “more random”.
My art professor wrote a book about famous artists and thinkers dying at 37: Raffaello, Parmigianino, Valentin de Boulogne, Cantarini, Watteau, Van Gogh, Toulouse-Lautrec, Tancredi, Gnoli, Manai, Majakovskij, Rimbaud, Byron, Mozart, Robespierre
https://www.ibs.it/trentasette-mistero-del-genio-adolescente-libro-flavio-caroli/e/9788804734017
Not a great book tbh.
Only dudes, though, right?
Why would that need to be proven? We’re the sample data. It’s implied.
The correctness of the sampling process still needs a proof. Like this.
What you’ve described would be like looking at a chart of various fluid boiling points at atmospheric pressure and being like “Wow, water boils at 100 C!” It would only be interesting if that somehow weren’t the case.
Where is the “Wow!” in this post? It states a fact, like “Water boils at 100C under 1 atm”, and shows that the student (ChatGPT) has correctly reproduced the experiment.
Why do you think schools keep teaching that “Water boils at 100C under 1 atm”? If it’s so obvious, should they stop putting it on the test and failing those who say it boils at “69C, giggity”?
Derek feeling the need to comment that the bias in the training data correlates with the bias of the corrected output of a commercial product just seemed really bizarre to me. Maybe it’s got the same appeal as a zoo or something, I never really got into watching animals be animals in a zoo.
Hm? Watching animals be animals at a zoo, is a way better sampling of how animals are animals, than for example watching that wildlife “documentary” where they’d throw lemmings of a cliff “for dramatic effect” (a “commercially corrected bias”?).
In this case, the “corrected output” is just 42, not 37, but as the temperature increases on the Y axis, we get a glimpse of internal biases, which actually let through other patterns of the training data, like the 37.
“we don’t need to prove the 2020 election was stolen, it’s implied because trump had bigger crowds at his rallies!” -90% of trump supporters
Another good example is the Monty Hall “paradox” where 99% of people are going to incorrectly tell you the chance is 50% because they took math and that’s how it works.
Just because something seems obvious to you doesn’t mean it is correct. Always a good idea to test your hypothesis.
Trump Rallies would be a really stupid sample data set for American voters. A crowd of 10,000 people means fuck all compared to 158,429,631. If OpenAI has been training their models on such a small pool then I’d call them absolute morons.
I agree that it would be a bad data set, but not because it is too small. That size would actually give you a pretty good result if it was sufficiently random. Which is, of course, the problem.
But you’re missing the point: just because something is obvious to you does not mean it’s actually true. The model could be trained in a way to not be biased by our number choice, but to actually be pseudo-random. Is it surprising that it would turn out this way? No. But to think your assumption doesn’t need to be proven, in such a case, is almost equivalent to thinking a Trump rally is a good data sample for determining the opinion of the general public.