

The mentioned but unsupported link to “general intelligence” reeks of bullshit to me. I don’t doubt a modified LLM (maybe an unmodified one as well) can beat lossless compression algorithms, but I doubt that’s very useful or impressive when you account for the model size and speed.
If you allow the model to be really huge in comparison to the input data it’s hard to prove you haven’t just memorized the training set.
How can they be lossless? Isn’t a neural network inherently lossy?
I suppose the compression process looks like this :
- call the model to predict the most probable next tokens (this is deterministic)
- encode next tokens by with its ranking in model prediction
If the model is good at predicting what the next token is, I suppose you need only 2bits to encode each token (for any of the top 4 predictions).
If you’re encoding the rankings as raw bits, how do you know when one ranking ends and the next begins? Zip compression solves this by using a BST, where you’d know if you need to keep reading by whether or not you’ve reached a leaf. But if there’s no reference data structure to tell you this, how do you know if you should read 4 bits ahead or 5?
Lossless in terms of compression is being able to reconstruct the original bits of a piece of media exactly from its compressed bits.
The thing that I’m wondering is how reliable this is
Depends on how you use it, if you just use it in place of finding repetition, it just means that our current way ain’t the mathematically best and AI can find better lol.
If you tried to “compress” a book into chatgpt tho yeah it’d probably be pretty lossy
This is the best summary I could come up with:
When an algorithm or model can accurately guess the next piece of data in a sequence, it shows it’s good at spotting these patterns.
The study’s results suggest that even though Chinchilla 70B was mainly trained to deal with text, it’s surprisingly effective at compressing other types of data as well, often better than algorithms specifically designed for those tasks.
This opens the door for thinking about machine learning models as not just tools for text prediction and writing but also as effective ways to shrink the size of various types of data.
Over the past two decades, some computer scientists have proposed that the ability to compress data effectively is akin to a form of general intelligence.
The idea is rooted in the notion that understanding the world often involves identifying patterns and making sense of complexity, which, as mentioned above, is similar to what good data compression does.
The relationship between compression and intelligence is a matter of ongoing debate and research, so we’ll likely see more papers on the topic emerge soon.
The original article contains 709 words, the summary contains 175 words. Saved 75%. I’m a bot and I’m open source!
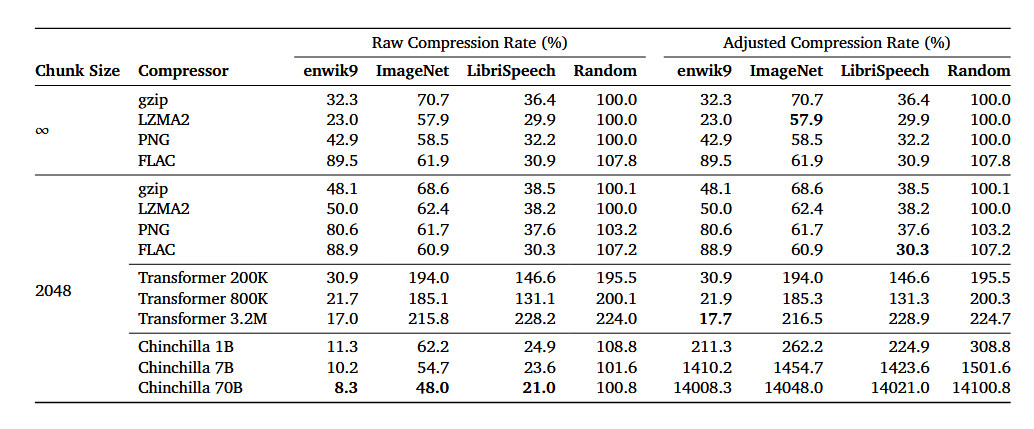
How do those figures compare to state of the art compression?
Chart This chart uses raw compression as well as adjusted. Adjusted includes the size of the model. For a lot of this, it really only works well on server scale data because the model for compressing them is so large. But it also leads some credence to other papers that show you can use compression to build generative models and k means to get decent results.
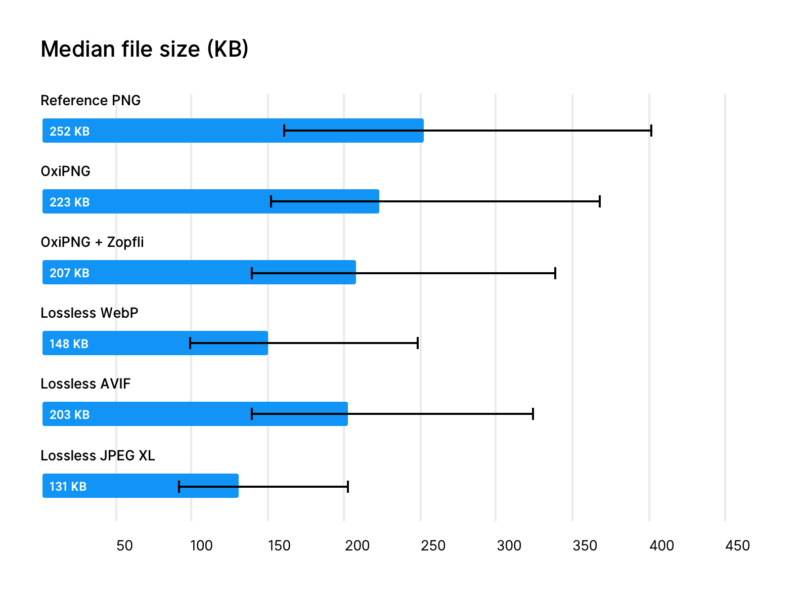
Lossless JPEG-XL and Webp are much better at compression:
Source: https://siipo.la/blog/whats-the-best-lossless-image-format-comparing-png-webp-avif-and-jpeg-xl
that means that 58.5% for PNG could be down to 30% when using a state-of-the-art lossless compression which is better than 48% by Chinchilla 70B
Is it me or it is only competitive on the Wikipedia dataset, which probably only contains examples from the training data of the model?
Hmm… Wonder how AI predicting what a photo of someone should look like will compare to how they actually do. Guess it’s not that different than the automatic filters phones have to make everyone look better.
deleted by creator
deleted by creator
Yeah I misunderstood. It just meant that AI is better at keeping that lossless data in small size.

{kind=link}
{kind=link}